Lifting a reloc based VM | Svartalfheim @ FCSC 2024
Intro
Svartalfheim is a weird reversing challenge. It seems like a simple x64 ELF with only a few bytes of machine code, but after playing with it, you might notice some quantum behaviours. The program might be patching itself when you are not looking at it, so stay alert 👀.
Challenge description
reverse | 467 pts 14 solves ⭐⭐⭐
Trouvez le flag accepté par le binaire.
Author: Quanthor_ic
Given files
Writeup
Overview
Things are already weird without opening up any disassembler:
file tells us the the binary is dynamically linked but ldd says otherwise.
$ file svartalfheim
svartalfheim: ELF 64-bit LSB executable, x86-64, version 1 (SYSV),
dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, no
section header
$ ldd svartalfheim
not a dynamic executable
Here is the decompiled code of the entrypoint.
int64_t _start()
{
int64_t path = '_';
syscall(sys_unlink {0x57}, &path);
int32_t fd = syscall(sys_open {2}, &path, O_CREAT | O_WRONLY);
syscall(sys_write {1}, fd, &__elf_header, 0x1a228);
syscall(sys_close {3}, fd);
syscall(sys_execve {0x3b}, &path, nullptr, nullptr);
}
Basically, it simply deletes a file named _ from the current directory, then
re-create it and open it write mode.
The process then dumps itself into the opened file, close it and execve the dumped file.
Cool so this should do absolutely nothing except calling itself endlessly.
But what if we give it a try:
./svartalfheim
Welcome to Svartalfheim
FCSC{test}
Nope
WTF is going on ?
Quantum binary
So first I wanted a way to see what was happening between each execution.
I patched the execve with a breakpoint in the binary.
It will now crash instead of starting itself again and I can inspect the
_ file before the next instance deletes it.
Here is the diff of the hexdump of the patched binary (breakpoint instead
of execve) with the hexdump of the _ file after a single execution:
$ diff svartalfheim_breakpointed.hex first_run.hex
517c517
< 00002040: 0700 0000 0000 0000 e821 0400 0000 0000 .........!......
---
> 00002040: 0700 0000 0000 0000 3037 0400 0000 0000 ........07......
519c519
< 00002060: 0800 0000 0000 0000 3000 0000 0000 0000 ........0.......
---
> 00002060: 0800 0000 0000 0000 6000 0000 0000 0000 ........`.......
A total of 3 bytes have changed, so I go check the corresponding addresses in my decompiler:
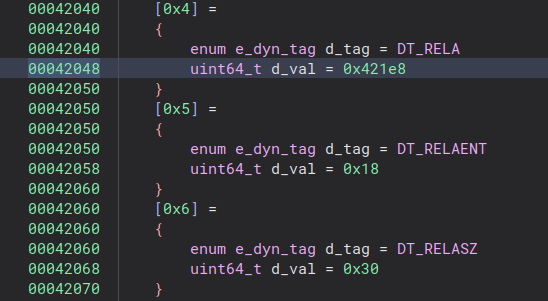
The first two bytes that are patched are the relocation table addr inside the dynamic table.
The last byte patched is the size of said relocation table.
This means that at the next execution, the program will have different relocations.
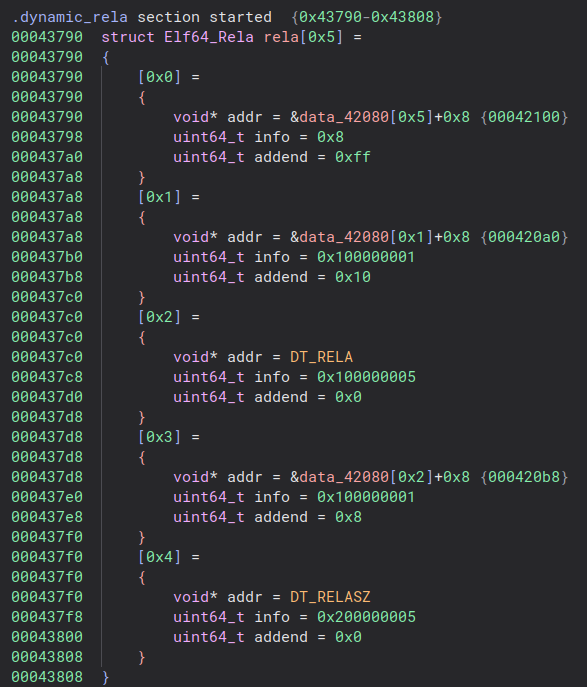
Maybe we should take a look at the original relocation table:
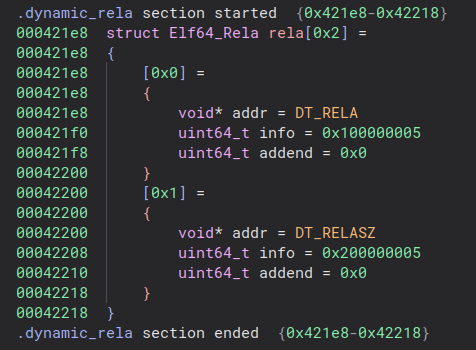
Unusual relocations indeed. So the first one points to the relocation table address inside the dynamic table and the second one to the relocation table size, also in the dynamic table, the two values that were patched in the next binary. We can already guess that the relocation table will be patched at every execution, running new relocations every time, just like a processor run instructions and increments its program counter. This might be a relocation based virtual machine.
Reloc based virtual machine
Figuring out the instruction set
So since the relocation table have changed in the next binary, let’s open this one and check the new relocation table:
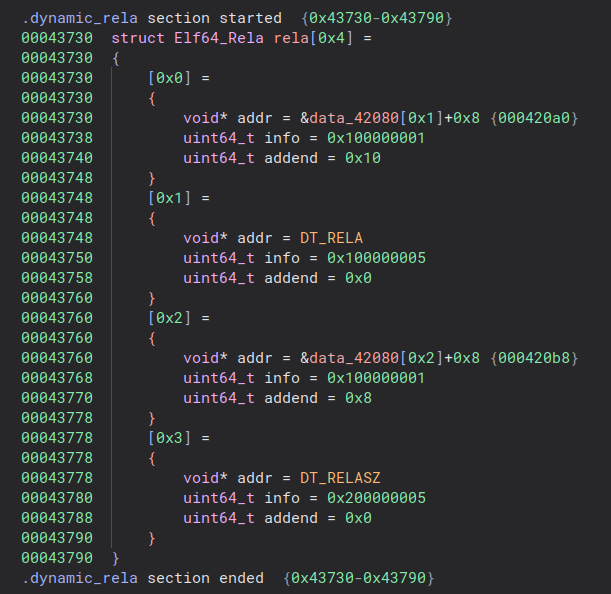
Once again we can see relocs pointing to DT_RELA and DT_RELASZ values, but there are also two other addresses that are patched.
When looking them up, we can see that these two addresses are located inside
the symbol table. To be precise, the values of symbol 1 and 2 are patched.
Below is the corresponding symbol table:
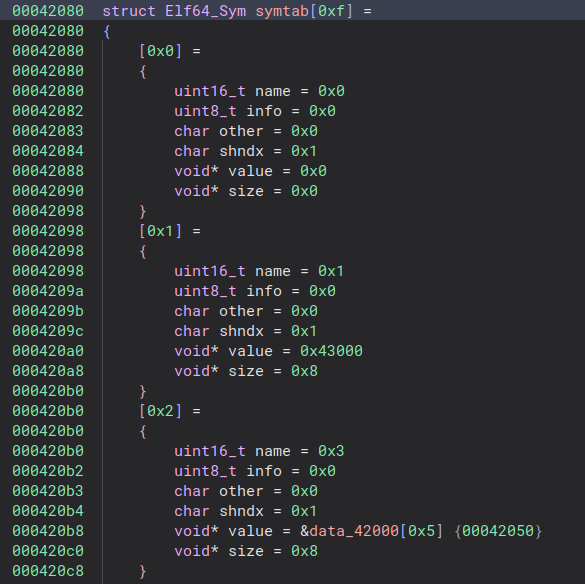
Great so now let’s run the binary a second time and inspect the third relocation table.
I will stop on this one a bit longer because it actually contains the entire instruction set.
But first, what is really happening ?
The relocation table holds … relocations indeed.
Relocations are applied by ldso when a process is loaded into memory
(so at execve).
Applying a relocation has different effects depending on the relocation type
(denoted in the lower 32 bits of the info field of the reloc).
However, most relocation types imply dereferencing the value of a symbol (see the above screenshot for an example of the symbol table) and storing it in the relocation address.
The said symbol is denoted by the higher 32 bits of the info field of the reloc.
Now let’s really look at the third relocation table and run it in our mind:
The first relocation is of type 0x8, and has symbol 0x0 (which mean no symbol)
It points to the address of the value of symbol 0x5.
Relocation type 0x8 will simply put its addend value at the address pointed by its addr field. Thus storing 0xff in the 0x5 symbol value
Basically this relocation is a mov mem, imm instruction.
Second relocation is of type 0x1 and symbol 0x1.
This relocation will take the value of symbol 0x1, add the reloc
addend value, and store the result at the relocation addr
So it looks like some sorts of add mem, reg, imm instruction, considering
symbols as registers.
I’ll do the third relocation and we will have the whole instruction set:
The type is 0x5, symbol 0x1. It will take the value of the corresponding symbol, dereference it, and store it in the reloc addr.
The assembly for this might look like mov mem, [reg]
Here we go, that’s it, an instruction set of 3 instructions, there isn’t even an instruction to branch or to add two registers together.
Let’s write an interpreter for the VM so we can debug it.
Writing the interpreter
Basically the interpreter will have multiple roles in the analysis:
- Get an execution trace and disassembly of the virtual machine
- Set breakpoints during execution
- Dump process to inspect the patched ELF at any stage easily and fast
#!/usr/bin/env python3
import struct
from typing import Optional
import copy
regs = {
0x42048: "DT_RELA",
0x42068: "DT_RELASZ",
0x42088: "r0",
0x420a0: "r1",
0x420b8: "r2",
0x420d0: "r3",
0x420e8: "r4",
0x42100: "r5",
0x42118: "r6",
0x42130: "r7",
0x42148: "r8",
0x42160: "r9",
0x42178: "r10",
0x42190: "r11",
0x421a8: "r12",
0x421c0: "r13",
0x421d8: "r14",
0x421f0: "r15",
0x42090: "r0.size",
0x420a8: "r1.size",
0x420c0: "r2.size",
0x420d8: "r3.size",
0x420f0: "r4.size",
0x42108: "r5.size",
0x42120: "r6.size",
0x42138: "r7.size",
0x42150: "r8.size",
0x42168: "r9.size",
0x42180: "r10.size",
0x42198: "r11.size",
0x421b0: "r12.size",
0x421c8: "r13.size",
0x421e0: "r14.size",
0x421f8: "r15.size"
}
class Stream:
i: int
buf: bytes
def __init__(self, buf) -> None:
self.pos = 0
self.buf = buf
def read_u8(self) -> Optional[int]:
try:
val = struct.unpack("<B", self.buf[self.pos:self.pos + 1])
self.pos += 1
return val[0]
except:
return None
def read_u16(self) -> Optional[int]:
try:
val = struct.unpack("<H", self.buf[self.pos:self.pos + 2])
self.pos += 2
return val[0]
except:
return None
def read_u32(self) -> Optional[int]:
try:
val = struct.unpack("<I", self.buf[self.pos:self.pos + 4])
self.pos += 4
return val[0]
except:
return None
def read_u64(self) -> Optional[int]:
try:
val = struct.unpack("<Q", self.buf[self.pos:self.pos + 8])
self.pos += 8
return val[0]
except:
return None
def is_done(self):
return self.pos >= len(self.buf)
class RelaEnt:
def __init__(self, stream):
self.addr = stream.read_u64()
self.type = stream.read_u32()
self.symbol = stream.read_u32()
self.addend = stream.read_u64()
class Rela:
def __init__(self, rela_addr, rela_size, elf):
self.rela_addr = rela_addr
self.rela_size = rela_size
self.elf = elf
def pop(self):
if self.rela_size <= 0:
return None
stream = Stream(self.elf.get_data(self.rela_addr, 0x18))
entry = RelaEnt(stream)
entry.offset = self.rela_addr
self.rela_addr += 0x18
self.rela_size -= 0x18
return entry
def peek(self):
if self.rela_size <= 0:
return None
stream = Stream(self.elf.get_data(self.rela_addr, 0x18))
entry = RelaEnt(stream)
entry.offset = self.rela_addr
return entry
class Symbol:
def __init__(self, data):
stream = Stream(data)
self.name = stream.read_u16()
self.info = stream.read_u8()
self.other = stream.read_u8()
self.shndx = stream.read_u32()
self.value = stream.read_u64()
self.size = stream.read_u64()
class Elf:
def __init__(self, path):
with open(path, 'rb') as f:
self._data = bytearray(f.read())
self.dynt_rela = 0x42048
self.dynt_relasz = 0x42068
self.symtab = 0x42080
self.breakpoints = {}
def dump(self, path):
with open(path, 'wb') as f:
f.write(self._data)
def get_data(self, addr, size):
addr -= 0x40000
return self._data[addr:addr + size]
def set_data(self, addr, data):
addr -= 0x40000
self._data[addr:addr + len(data)] = data
def set_flag(self, flag):
addr = 0x5a100
addr -= 0x40000
self._data[addr:addr + len(flag)] = flag
def get_rela(self):
rela_addr = Stream(self.get_data(self.dynt_rela, 8)).read_u64()
rela_size = Stream(self.get_data(self.dynt_relasz, 8)).read_u64()
return Rela(rela_addr, rela_size, self)
def get_symbol(self, i):
sym_data = self.get_data(self.symtab + 0x18 * i, 0x18)
return Symbol(sym_data)
def apply_relocs(self):
rela = self.get_rela()
patched_code = False
asm = ""
while True:
entry = rela.pop()
if not entry:
break
symbol = self.get_symbol(entry.symbol)
dst_name = regs[entry.addr] if entry.addr in regs else f'[{hex(entry.addr)}]'
line = f'{hex(entry.offset)}: '
if entry.type == 1:
data_int = (symbol.value + entry.addend) % 2**64
data = struct.pack('<Q', data_int)
line += f'add {dst_name}, r{entry.symbol}, ${hex(entry.addend)}'
elif entry.type == 5:
data = self.get_data(symbol.value + entry.addend, symbol.size)
line += f'mov {dst_name}, [r{entry.symbol}].{symbol.size}'
if entry.addend != 0:
raise
elif entry.type == 8:
data_int = entry.addend
data = struct.pack('<Q', data_int)
src_name = f'&{regs[entry.addend]}' if entry.addend in regs else f'${hex(entry.addend)}'
line += f'mov {dst_name}, {src_name}'
else:
print(hex(entry.type))
raise
line += ' ' * (50 - len(line)) + f'# {bytes(data).hex()}'
if entry.addr > entry.offset and entry.addr < 0x49000:
next_instr = rela.peek()
if not (entry.addr >= next_instr.offset and entry.addr < next_instr.offset + 0x18):
line += " PATCHING FAR"
else:
line += ' PATCHING CODE'
asm += line + '\n'
self.set_data(entry.addr, data)
if entry.addr >= 0x41000 and entry.addr < 0x41083:
patched_code = True
asm += '#End of block\n'
return asm, patched_code
def main():
elf = Elf('./svartalfheim')
asm = ""
n = 0
while n <= 7:
step_asm, patched_code = elf.apply_relocs()
if patched_code:
asm += '# NATIVE CODE LOADING:\n'
n += 1
elf.dump(f'./dumps/pydumped{n}')
asm += step_asm
print(asm)
if __name__ == "__main__":
main()
This interpreter stops every time that the VM patches the native code section of the binary, this way I can stop whenever IO is performed, dump the binary and analyse it.
The VM patches the native code a total of 7 times:
- Setup a syscall to write the prompt on stdout
- Immediately after, reset the native code to its original content
- Setup a syscall to read the flag from stdin
- Immediately after, reset the native code to its original content
- Setup a syscall to write the flag validation
- Immediately after, reset the native code to its original content
- Setup a syscall to exit the program instead of the
execveit again
Investigating the third dumped binary will show us the flag address given to read, which will allow us to inject it in our interpreter:
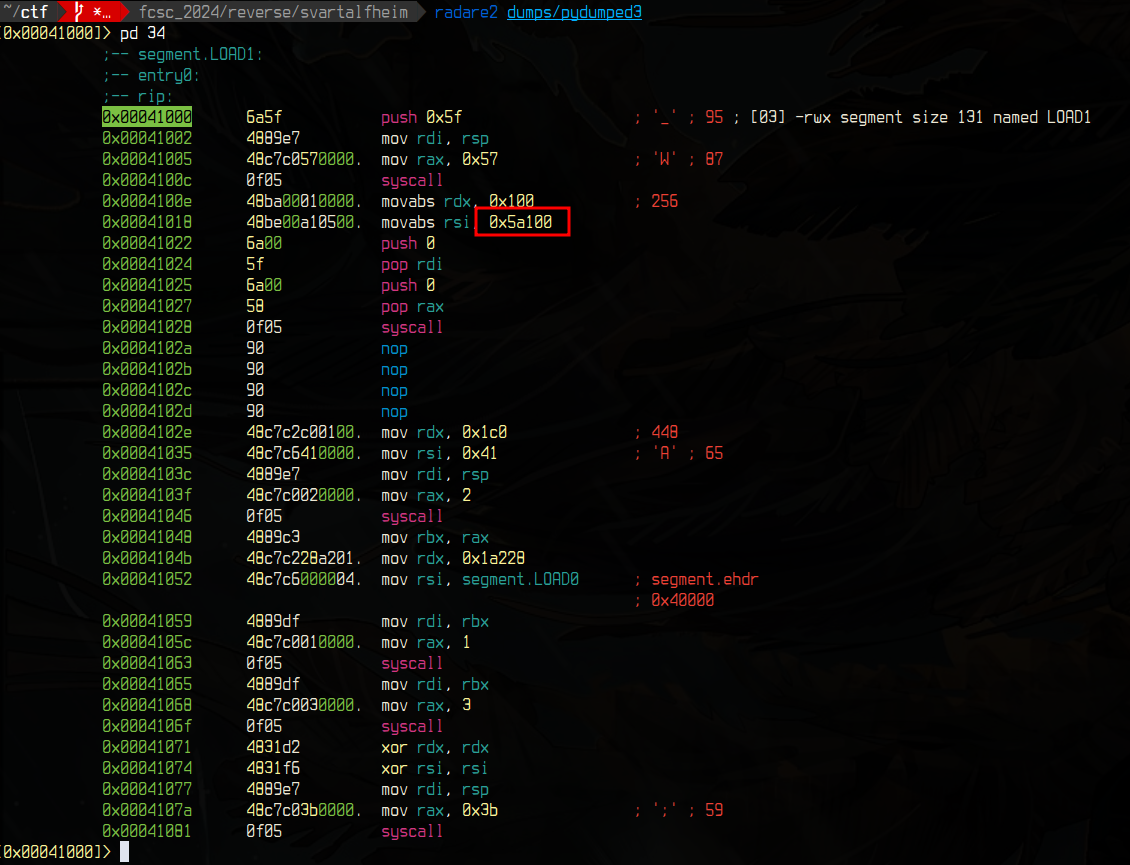
The interpreter also builds a disassembled execution trace:
I tried to make it readable as if it was intel assembly.
I added some comments for easier analysis:
- NATIVE CODE LOADING means that this block (a complete run of a single relocation table) has patched the native code section
- The commented hexstring is the data that is being outputed in the destination operand
- PATCHING CODE means that this instruction has a destination address pointing to the next instruction, meaning it is trying to patch its own code
- PATCHING FAR is the same but on an instruction of the same block but not the next one
These were really helpful during analysis to have a reminder to check for code patching.
You might be saying that the example assembly below doesn’t correspond to the
instruction set defined above as there was no such instruction as
add reg, reg, imm, it is indeed true, but the trick is that every register
are memory mapped (since they are simply symbols in the symtab of the ELF), so a memory deref can actually be a register and my disassembler lifts this.
0x48080: mov [0x480f0], $0xffffffffffffffa0 # a0ffffffffffffff PATCHING FAR
0x48098: add [0x480b0], r4, $0x480d8 # f080040000000000 PATCHING CODE
0x480b0: mov [0x480f0], $0x0 # 0000000000000000 PATCHING FAR
0x480c8: add r1, r1, $0x0 # 1036040000000000
0x480e0: add r1, r1, $0x0 # 1036040000000000
0x480f8: add r1, r1, $0x10 # 2036040000000000
0x48110: mov DT_RELA, [r1].8 # 5881040000000000
0x48128: add r2, r1, $0x8 # 2836040000000000
0x48140: mov DT_RELASZ, [r2].8 # 7800000000000000
#End of block
0x48158: mov r7, $0x5 # 0500000000000000
0x48170: add r1, r1, $0x10 # 3036040000000000
0x48188: mov DT_RELA, [r1].8 # d081040000000000
0x481a0: add r2, r1, $0x8 # 3836040000000000
0x481b8: mov DT_RELASZ, [r2].8 # f000000000000000
#End of block
# NATIVE CODE LOADING:
0x481d0: mov [0x4100e], $0xba48 # 48ba000000000000
0x481e8: mov [0x41016], $0xbe480000 # 000048be00000000
0x48200: mov [0x4101e], $0x6a5f016a00000000 # 000000006a015f6a
0x48218: mov [0x41026], $0x90909090050f5801 # 01580f0590909090
0x48230: add [0x41010], r7, $0x0 # 0500000000000000
0x48248: add [0x4101a], r8, $0x0 # 23a2050000000000
0x48260: add r1, r1, $0x10 # 4036040000000000
0x48278: mov DT_RELA, [r1].8 # c082040000000000
0x48290: add r2, r1, $0x8 # 4836040000000000
0x482a8: mov DT_RELASZ, [r2].8 # c000000000000000
#End of block
Side channel attempt
My first attempt at a solver was really simple, I thought that maybe the VM would check bytes one by one.
So I added a method to inject the flag into my interpreter’s memory and tried to bruteforce the first char, watching for the length of the execution trace every time.
But all 256 possible bytes gave the same number of instructions
At this points I was thinking about lifting the code a little more to reduce the trace size before reading it, but I was in the mood to read 65000+ lines of the same 3 instructions.
Analysing the execution trace
Just kidding I did not actually read the whole execution trace.
I knew that the flag start with FCSC{, so I dumped 2 execution trace:
- One with the flag as
FCSC{test - The other one with
HCSC{test
I put them side by side (FCSC{ on the left, HCSC{ on the right), jumped right after the read call, and started comparing them, and lifting the code on paper.
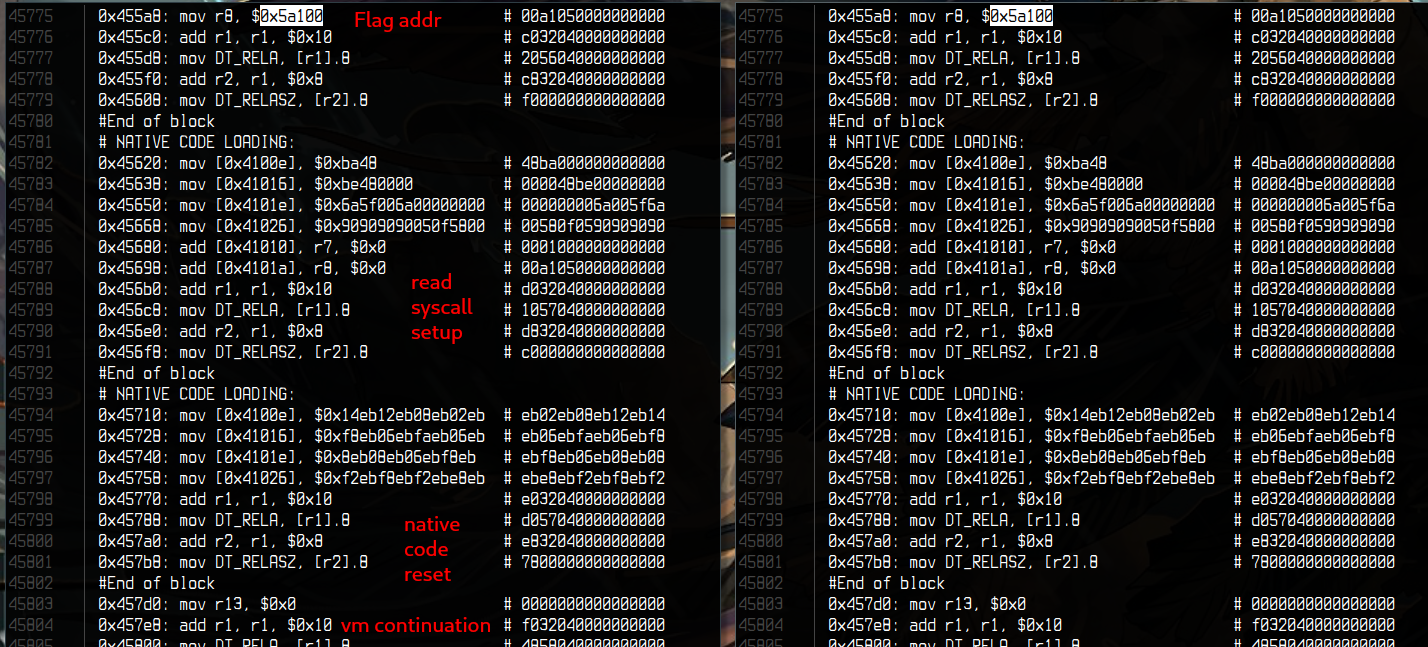
I will not show you the whole execution trace to keep your eyes safe, but
the VM starts by a bunch of mov reg, imm instructions to initialize some
variables.
And then a fun pattern appears:
add mem, reg, reg

These three instructions together can actually be lifted to add r13.b, r6, r13
It is crucial to understand this simple pattern before we continue to how branching are handled in this VM.
Start by looking the first instruction: it takes the value of r13, add 0,
and store it at 0x45a50. The first thing to notice is that add mem, reg, $0x0 is actually equivalent to a mov mem, reg, but there is no such
instruction in our instruction set (mov mem, [reg] will deref the reg) thus the add instruction trick.
Then if you look the destination address, it points to the the next instruction addend. Looking at the comment, we know that the output value is 0x0 on 8 bytes.
So now when we look at the second instruction, it is indeed add r13, r6, $0x0, but said immediate $0x0 was patched by previous instruction, with the
value of r13, even if the instruction add an immediate, in this context,
the immediate was patched with a register. Thus performing a add mem, reg, reg
The third instruction simply zeroes out the 7 higher bytes of the r13
register, my disassembler did not lift the addresses of the higher bytes of
regs but trust me on this one.
The comment on the second instruction shows us that the addition had a result of 0x1 (64 bits little endian) (r6 had value 1), so these 3 instructions simply increment r13.
Lookup tables
I skipped a few instructions, all you need to know is that r3 points
to the first byte of the flag, and that r12 was initialized with a byte
coming from an array indexed with the same counter as the flag.
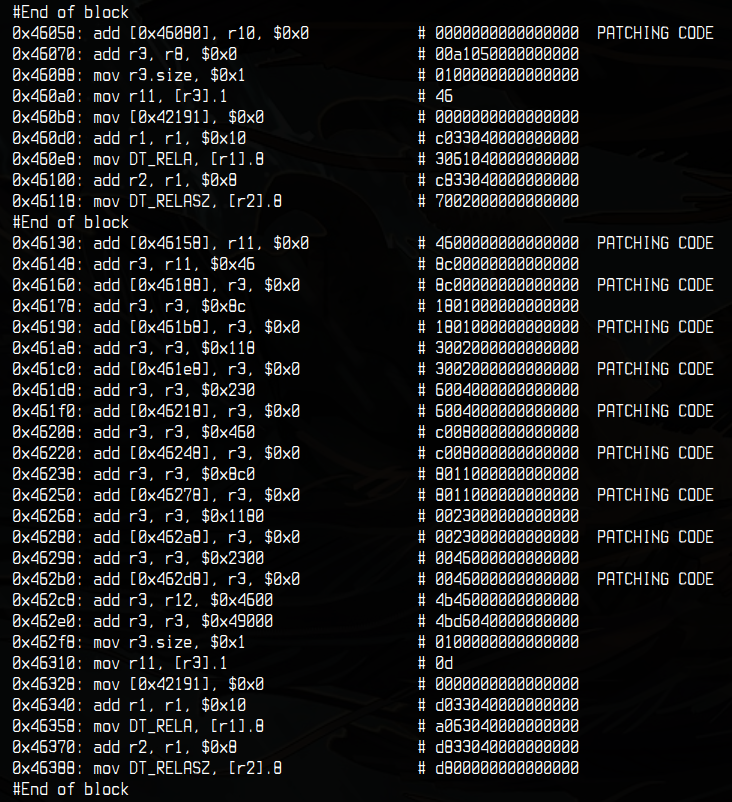
The first block simply loads the current flag byte in r11 (0x46 = 'F')
and the second one basically substitutes the byte from the flag based on a lookup table.
The LuT is indexed based on the flag byte and r12, which I assume is some
sort of nonce to add the information of the position of the byte in the
flag during the substitution.
Here is a c equivalent I lifted on paper:
uint64_t r12 = nonce[i];
uint64_t r11 = flag[i];
uint64_t r3 = (r11 << 32) + r12;
uint64_t *LuT = 0x49000;
r11 = *(LuT + r3);
The next few blocks are not that important, they store the LuTed byte in memory, increment string iterators and decrement size counters
But then comes the one most important code pattern of this VM:
Branching
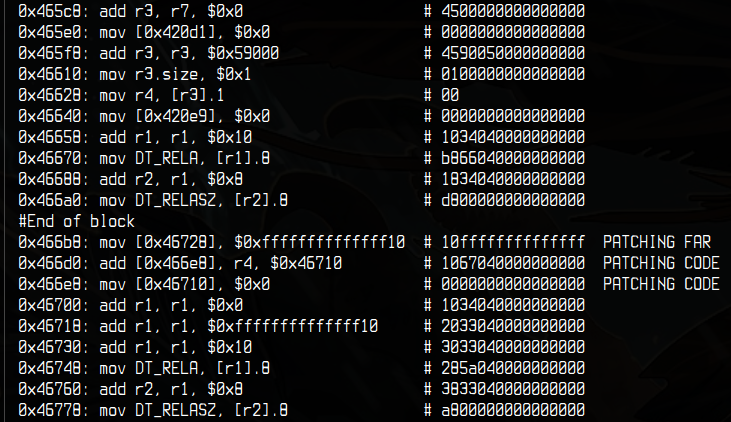
These two blocks perform a branch
It essentially is a test r7, r7; jne mem
Here is how it works after lifting:
// First block
jump_table = 0x59000;
r4 = jump_table[r7]; // r7 is remaining flag len
// Second block
r1 = r1 + 0x10 - 0xf0 + r4;
// DT_RELA = r1, r1 is the program counter
So 0x59000 contains a jump table indexed on the remaining flag size.
Here you can see at instruction 0x46628, the jump offset is in the comment.
I noticed it changed when r7 reached 0.
It is essentialy the first for loop iterating on the flag, applying lookup
tables on each byte.
Flag checking
After that there is a really similar block of code, also performing lookups of some sort I did not really bother to understand (as the ones of the previous step) because I found a really interesting branch which was not a loop.
I notice a similar pattern than the for loop above, sligthly different but still some kind of jump table.
What stroke me is that as you can see on the screenshot bellow, it was
the first time in the whole execution trace, that my purposely wrong flag, ran
to a different branch than the one starting with FCSC{
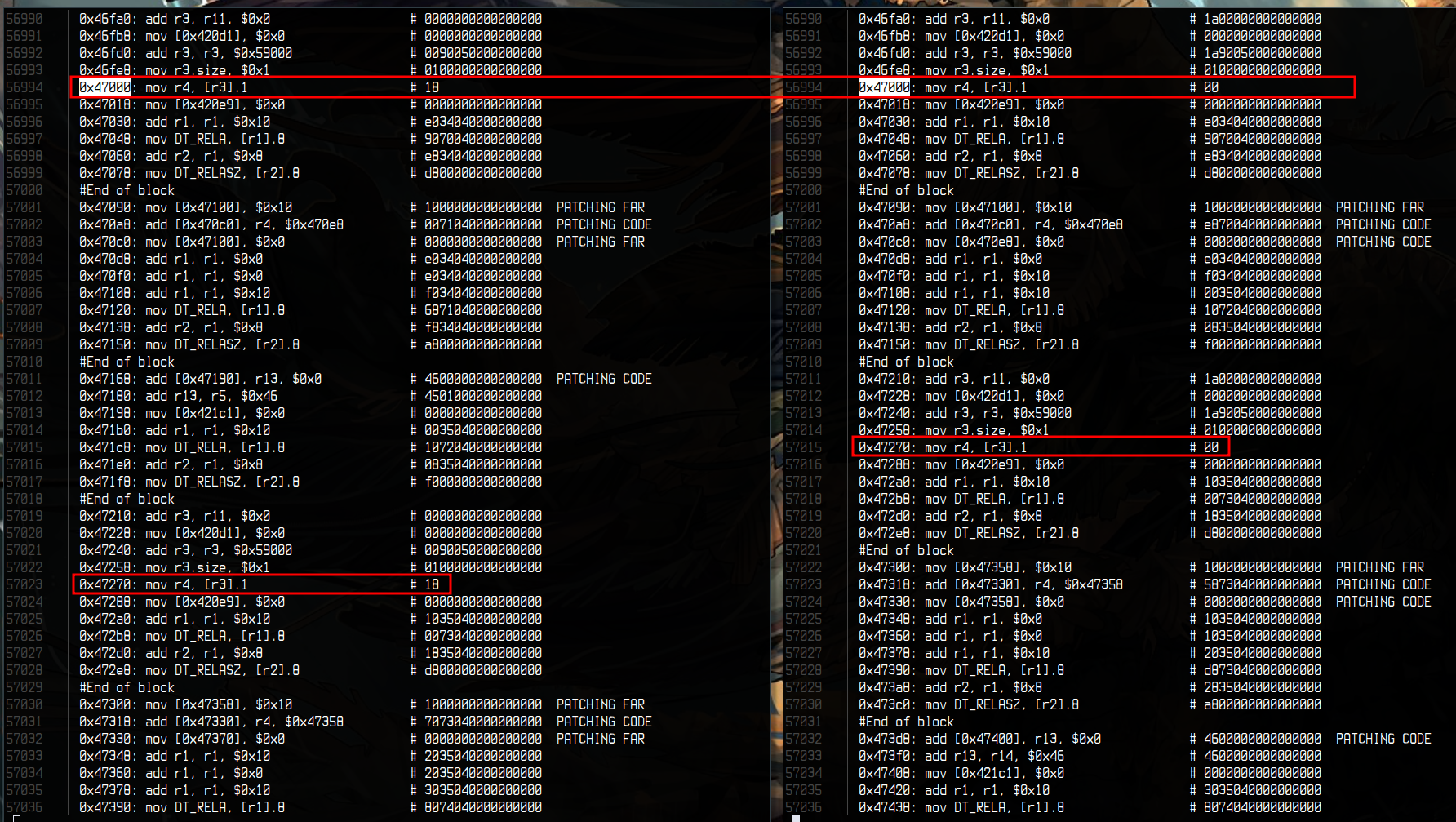
What I did not notice at first is that there are two different branchments in
the screenshot (with the jump offsets marked in red). I noticed it quickly and
backported it to my solver.
I do not actually know what is the meaning of these 2 checks regarding the
previous look up tables but all I know is that I needed to hit jump
offset 0x18 twice for a flag byte to be valid.
So I modified my interpreter to add a breakpoint at the addresses marked in red,
check the value moved in r4 is 0x18.
And then bruteforced byte by byte:
While bruteforcing the nth byte, I need to hit the breakpoint succesfully (with 0x18 in r4) 2*n times. If the breakpoint check fails once then the byte is fucked up.
Solver
Here is the complete solver code, with the interpreter, correct breakpoints and bruteforcing
#!/usr/bin/env python3
import struct
from typing import Optional
import copy
regs = {
0x42048: "DT_RELA",
0x42068: "DT_RELASZ",
0x42088: "r0",
0x420a0: "r1",
0x420b8: "r2",
0x420d0: "r3",
0x420e8: "r4",
0x42100: "r5",
0x42118: "r6",
0x42130: "r7",
0x42148: "r8",
0x42160: "r9",
0x42178: "r10",
0x42190: "r11",
0x421a8: "r12",
0x421c0: "r13",
0x421d8: "r14",
0x421f0: "r15",
0x42090: "r0.size",
0x420a8: "r1.size",
0x420c0: "r2.size",
0x420d8: "r3.size",
0x420f0: "r4.size",
0x42108: "r5.size",
0x42120: "r6.size",
0x42138: "r7.size",
0x42150: "r8.size",
0x42168: "r9.size",
0x42180: "r10.size",
0x42198: "r11.size",
0x421b0: "r12.size",
0x421c8: "r13.size",
0x421e0: "r14.size",
0x421f8: "r15.size"
}
class Stream:
i: int
buf: bytes
def __init__(self, buf) -> None:
self.pos = 0
self.buf = buf
def read_u8(self) -> Optional[int]:
try:
val = struct.unpack("<B", self.buf[self.pos:self.pos + 1])
self.pos += 1
return val[0]
except:
return None
def read_u16(self) -> Optional[int]:
try:
val = struct.unpack("<H", self.buf[self.pos:self.pos + 2])
self.pos += 2
return val[0]
except:
return None
def read_u32(self) -> Optional[int]:
try:
val = struct.unpack("<I", self.buf[self.pos:self.pos + 4])
self.pos += 4
return val[0]
except:
return None
def read_u64(self) -> Optional[int]:
try:
val = struct.unpack("<Q", self.buf[self.pos:self.pos + 8])
self.pos += 8
return val[0]
except:
return None
def is_done(self):
return self.pos >= len(self.buf)
class RelaEnt:
def __init__(self, stream):
self.addr = stream.read_u64()
self.type = stream.read_u32()
self.symbol = stream.read_u32()
self.addend = stream.read_u64()
class Rela:
def __init__(self, rela_addr, rela_size, elf):
self.rela_addr = rela_addr
self.rela_size = rela_size
self.elf = elf
def pop(self):
if self.rela_size <= 0:
return None
stream = Stream(self.elf.get_data(self.rela_addr, 0x18))
entry = RelaEnt(stream)
entry.offset = self.rela_addr
self.rela_addr += 0x18
self.rela_size -= 0x18
return entry
def peek(self):
if self.rela_size <= 0:
return None
stream = Stream(self.elf.get_data(self.rela_addr, 0x18))
entry = RelaEnt(stream)
entry.offset = self.rela_addr
return entry
class Symbol:
def __init__(self, data):
stream = Stream(data)
self.name = stream.read_u16()
self.info = stream.read_u8()
self.other = stream.read_u8()
self.shndx = stream.read_u32()
self.value = stream.read_u64()
self.size = stream.read_u64()
class Elf:
def __init__(self, path):
with open(path, 'rb') as f:
self._data = bytearray(f.read())
self.dynt_rela = 0x42048
self.dynt_relasz = 0x42068
self.symtab = 0x42080
self.breakpoints = {}
def dump(self, path):
with open(path, 'wb') as f:
f.write(self._data)
def get_data(self, addr, size):
addr -= 0x40000
return self._data[addr:addr + size]
def set_data(self, addr, data):
addr -= 0x40000
self._data[addr:addr + len(data)] = data
def set_flag(self, flag):
addr = 0x5a100
addr -= 0x40000
self._data[addr:addr + len(flag)] = flag
def get_rela(self):
rela_addr = Stream(self.get_data(self.dynt_rela, 8)).read_u64()
rela_size = Stream(self.get_data(self.dynt_relasz, 8)).read_u64()
return Rela(rela_addr, rela_size, self)
def get_symbol(self, i):
sym_data = self.get_data(self.symtab + 0x18 * i, 0x18)
return Symbol(sym_data)
def set_breakpoint(self, addr, func, res):
self.breakpoints[addr] = (func, res)
def apply_relocs(self):
rela = self.get_rela()
patched_code = False
asm = ""
while True:
entry = rela.pop()
if not entry:
break
symbol = self.get_symbol(entry.symbol)
dst_name = regs[entry.addr] if entry.addr in regs else f'[{hex(entry.addr)}]'
line = f'{hex(entry.offset)}: '
if entry.type == 1:
data_int = (symbol.value + entry.addend) % 2**64
data = struct.pack('<Q', data_int)
line += f'add {dst_name}, r{entry.symbol}, ${hex(entry.addend)}'
elif entry.type == 5:
data = self.get_data(symbol.value + entry.addend, symbol.size)
line += f'mov {dst_name}, [r{entry.symbol}].{symbol.size}'
if entry.addend != 0:
raise
elif entry.type == 8:
data_int = entry.addend
data = struct.pack('<Q', data_int)
src_name = f'&{regs[entry.addend]}' if entry.addend in regs else f'${hex(entry.addend)}'
line += f'mov {dst_name}, {src_name}'
else:
print(hex(entry.type))
raise
line += ' ' * (50 - len(line)) + f'# {bytes(data).hex()}'
if entry.addr > entry.offset and entry.addr < 0x49000:
next_instr = rela.peek()
if not (entry.addr >= next_instr.offset and entry.addr < next_instr.offset + 0x18):
line += " PATCHING FAR"
else:
line += ' PATCHING CODE'
asm += line + '\n'
if entry.offset in self.breakpoints:
stop = not self.breakpoints[entry.offset][0](self, entry, line, data, self.breakpoints[entry.offset][1])
if stop:
return asm, stop
self.set_data(entry.addr, data)
if entry.addr >= 0x41000 and entry.addr < 0x41083:
patched_code = True
asm += '#End of block\n'
return asm, patched_code
def fetch_r4(elf, entry, asm, data, res):
if data != b'\x00':
res.append(True)
return True
else:
return False
def check(elf, entry, asm, data):
if data == b'\x00':
print(asm)
def main():
elf = Elf('./svartalfheim')
asm = ""
n = 0
while n <= 3:
#print('---')
step_asm, patched_code = elf.apply_relocs()
if patched_code:
asm += '# NATIVE CODE LOADING:\n'
n += 1
elf.dump(f'./dumps/pydumped{n}')
asm += step_asm
flag = bytearray(0x46)
for i in range(0x46):
for b in range(0x30, 127):
n = 4
flag[i] = b
before_read = copy.deepcopy(elf)
res = []
before_read.set_breakpoint(0x47000, fetch_r4, res)
before_read.set_breakpoint(0x47270, fetch_r4, res)
before_read.set_flag(flag)
while n < 7:
step_asm, patched_code = before_read.apply_relocs()
if patched_code:
asm += '# NATIVE CODE LOADING:\n'
n += 1
elf.dump(f'./dumps/pydumped{n}')
break
asm += step_asm
if len(res) == 2 * (i + 1):
print(flag)
break
#print(asm)
if __name__ == "__main__":
main()
$ ./solve.py
bytearray(b'F\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00')
bytearray(b'FC\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00')
bytearray(b'FCS\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00')
...
bytearray(b'FCSC{162756828312aad562394d47c854134803a092d7f5b9eb795528f4a0f16f7c65}')
$ ./svartalfheim
Welcome to Svartalfheim
FCSC{162756828312aad562394d47c854134803a092d7f5b9eb795528f4a0f16f7c65}
Well done!