Decompiling a multi-process VM back to C | Megalosaure @ FCSC 2024
Intro
Yes it’s the third year in a row that I writeup the dinosaur reverse challenge.
But this time it is neither a math or puzzle challenge.
We are instead met with a program that takes 20 minutes to validate the input and forks tens of thousands of processes.

Challenge description
reverse | 487 pts 6 solves ⭐⭐⭐
Voici un binaire qui vérifie si ce qu'on lui passe est le flag. À vous de jouer !
Author: Cryptanalyse
Given files
Writeup
Overview
Nothing out of the ordinary at the first look.
$ file megalosaure
megalosaure: ELF 64-bit LSB pie executable, x86-64, version 1
(SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2,
BuildID[sha1]=b8bd171568d3bd03eca826edb869205684411dab, for GNU/Linux 3.2.0,
stripped
Dynamic analysis however … the binary first tells us to add a
capability to the binary, stracing and gdb will thus require higher
privileges to not drop said capability.
stracing will show us that the program starts by creating about 10 thousands pipes. Before prompting for the flag, inputting
a correctly formatted FCSC{...} flag will then cause the program
to fork endlessly for about 20 minutes before refusing the flag.
Code analysis
Main function
Here is a decompiled main function.
We can see that the code creates the pipes in setup_process_limit_and_IPC,
then creates a shared memory mapping..
It will then ask for the flag, check its format, and split the
input into 0x12 uint32_t.
These int are then xored in the shared memory by groups of two
and the same function is ran 0x2c times for each group but more
on this later.
Once this is done, the program saves some bytes in the shared
memory else where, and shift the global shared memory pointer,
before doing the same thing for the next 2 int in the input.
The final check simply is an equality test of all the saved values mentionned above against an hardcoded reference array.
uint32_t* shared_mem = nullptr;
int32_t main(int32_t argc, char** argv, char** envp)
{
setup_process_limit_and_IPC();
shared_mem = mmap(nullptr, 0x100000, 3, 0x21, 0xffffffff, 0);
if (shared_mem == -1)
{
perror("mmap");
exit(1);
}
int32_t* shared_mem_original = shared_mem;
puts("Enter the flag:");
char input[0x46];
memset(&input, 0, 0x46);
if (read(0, &input, 0x46) <= 0)
{
perror("read");
exit(1);
}
if (check_format(&input) != 0)
{
puts("Wrong flag format!");
exit(1);
}
uint32_t (* input_ints)[0x12] = &input;
for (int32_t i = 0; i <= 0x11; i += 2)
{
shared_mem[0] = (shared_mem[0] ^ input_ints[i]);
shared_mem[1] = (shared_mem[1] ^ input_ints[i + 1]);
for (int32_t j = 0; j < 0x2c; j += 1)
start_pod(pod_infos[j].n_children, code, 9);
*(uint64_t*)(((((i + (i >> 0x1f)) >> 1) + 0x100) << 3) + shared_mem_original)
= *(uint64_t*)(shared_mem + 0xb0);
shared_mem = &shared_mem[0x2c];
}
shared_mem = shared_mem_original;
int64_t lose = 0;
for (int32_t i = 0; i <= 8; i++)
lose = (lose | (ref[i] ^ *(uint64_t*)(shared_mem + 0x800) + (i_1 << 3)));
if (lose != 0)
puts("Nope.");
else
puts("Win!!");
if (munmap(shared_mem, 1) != 0xffffffff)
return 0;
perror("munmap");
exit(1);
}
Check format
Let’s take a quick look at the check_format function:
uint64_t check_format(int32_t* input)
{
shared_mem[0] = input[0];
shared_mem[1] = 0x1337;
shared_mem[2] = 0xa4e1a60a;
start_pod(5, check_bytecode, 0x78 / 10);
return 0 | shared_mem[0] | shared_mem[1] | shared_mem[2];
}
We can see that it initializes the shared memory with the first
uint32_t of the input then starts the same start_pod function
than in main.
Start pod
The start_pod function takes as first parameter what I called a
pod_info struct, which is just two uint32_t, the first one
is the number of children the pod will fork, the second one is an
offset in some array of uint16_t I called code given in
parameter, you will understand the name really fast once we check
the child function.
The last parameter is the size of a single code block given to
child. Thus offsetting by this much between each fork.
In my terminology, a pod is a complete run of all the children
denoted by their pod_info and associated code.
__pid_t start_pod(int32_t pod_info[2], uint16_t* code, int64_t code_size)
{
for (int32_t i = 0; i < pod_info[0]; i = (i + 1))
{
pid_t pid = fork();
if (pid == 0xffffffff)
{
perror("fork");
exit(1);
}
if (pid == 0)
{
child(&code[(i + pod_info[1]) * code_size]);
/* no return */
}
}
__pid_t i;
do
{
i = wait(nullptr);
} while (i > 0);
return i;
}
Child
We are met with a while true loop, which selects an uint16_t
from the code array and dispatches it in a huge switch.
I immediatly recognize the pattern of a virtual machine,
and start identifying the instruction pointer ip and the
stack by looking the first few instructions of the switch.
I will not show how I reversed all the instruction as many of them are really similar but I will show the interesting ones.
void child(uint16_t* code) __noreturn
{
uint32_t stack[0x400];
memset(&stack, 0, 0x1000);
int32_t next_ip = 0;
int32_t sp = 0;
uint16_t opcode;
while (true)
{
int32_t ip = netx_ip;
next_ip = ip + 1;
opcode = code[ip];
switch (opcode)
{
case 0x0:
{
...
}
case 0x1:
...
}
}
if (opcode != 0x12)
exit(1);
exit(0);
}
Instruction set analysis
Push
First let’s look at opcodes 0x1 and 0x2.
These are how I recognized and was able to rename the stack memory and stack pointers.
We can see that the first instruction takes one operand right
after the opcode, it then increments the stack pointer, fetches
an uint32_t from the shared memory, indexed by the first
operand, and stores it in the stack.
Basically a push mem instruction
The second one is really similar but takes two immediate operands,
both operands are uint16_t but they are packed as a single
uint32_t and stored on the stack, so this is the push imm
instruction
case 1:
{
int32_t operand_ptr = next_ip;
next_ip = (operand_ptr + 1);
int32_t old_sp = sp;
sp = old_sp + 1;
stack[old_sp] = shared_mem[code[operand_ptr]];
break;
}
case 2:
{
int32_t operand2_ptr = next_ip + 1;
int64_t operand1_ptr = next_ip;
next_ip = operand2_ptr + 1;
int32_t old_sp = sp;
sp = old_sp + 1;
stack[old_sp] = code[operand1_ptr] | (code[operand2_ptr] << 0x10);
break;
}
Pop
This is the inverse operation, takes an uint32_t from the stack
and stores it in the shared memory indexed on the instruction’s
operand.
case 4:
{
int32_t operand_ptr = next_ip;
next_ip = operand_ptr + 1;
uint32_t operand = code[operand_ptr];
sp = sp - 1;
int32_t val = stack[sp];
stack[sp] = 0;
shared_mem[operand] = val;
break;
}
Add
I will show only a single arithmetic instruction, all the others work in a similar way:
This one pops two operands from the stack, add them together, and stores the result back on the stack.
So we now know that this VM is stack based, similar to python
or WASM bytecode, operands and result of each instruction are
fetched and stored from/on the stack.
case 6:
{
int32_t first_op_ptr = (sp - 1);
int32_t stack_op = stack[first_op_ptr];
stack[first_op_ptr] = 0;
int32_t second_op_ptr = first_op_ptr - 1;
int32_t stack_op2 = stack[second_op_ptr];
stack[second_op_ptr] = 0;
sp = second_op_ptr + 1;
stack[second_op_ptr] = stack_op2 + stack_op;
break;
}
IPC
Before doing more work, two other instructions are really important, check the code first:
case 3:
{
int32_t operand_ptr = next_ip;
next_ip = (operand_ptr + 1);
uint32_t operand_1 = code[operand_ptr];
sp = sp - 1;
int32_t val = stack[sp];
stack[sp] = 0;
for (int32_t i = 0; i < operand; i++)
{
int32_t operand_i_ptr = next_ip;
next_ip = operand_i_ptr + 1;
if (write(pipes[code[operand_i_ptr]][1], &val, 4) == -1)
{
perror("write");
exit(1);
}
}
break;
}
This instruction takes one operand from the stack and one operand after the opcode.
The operand encoded in the instruction is used to know how many more operands are left.
For each of them, the instruction will write the stack operand in the pipe corresponding to the current operand.
We can guess that this is how IPC is performed between each child.
So let’s look at the read instruction:
It works in a really similar way and takes the same operand,
except that this time it will setup an epoll instance to read on
very pipe given as operand and store the read output on the
stack for each operand.
case 0:
{
int32_t n_operands_ptr = next_ip;
next_ip = n_operands_ptr + 1;
uint32_t n_operands = code[n_operands_ptr];
int32_t epoll = epoll_create1(0);
if (epoll == 0xffffffff)
{
perror("epoll_create1");
exit(1);
}
for (int32_t i = 0; i < n_operands; i++)
{
int32_t n_operands_i_ptr = next_ip;
next_ip = n_operands_i_ptr + 1;
int32_t fd = pipes[code[n_operands_i_ptr]][0];
int32_t epoll_event = 1;
int64_t var_1100_1 = fd | (i << 0x20);
if (epoll_ctl(epoll, 1, fd, &epoll_event) != 0)
{
perror("epoll_ctl");
exit(1);
}
}
uint32_t n_operands_cpy = n_operands;
do
{
struct epoll_event events;
int32_t nb_events = epoll_wait(epoll, &events, 1, 0xffffffff);
for (int32_t j = 0; j < nb_events; j++)
{
// Weird but basically recovers the FD from the event
int64_t fd = *(j * 0xc + &var_8) - 0x1104;
if (read(fd, &stack[(fd >> 0x20) + sp], 4) <= 0)
{
perror("read");
exit(1);
}
}
n_operands_cpy = n_operands_cpy - 1;
} while (n_operands_cpy != 0);
sp = sp + n_operands;
if (close(epoll) != 0)
{
perror("close");
exit(1);
}
break;
}
Disassembling
Right, so let’s not look too much at the IPC thingy.
I will start by disassembling the byte code of independant children, then we will see if we can deduce patterns.
So I implemented a binaryninja plugin (my predilection decompiler) for the VM.
import struct
from binaryninja import *
tI = lambda e: InstructionTextToken(InstructionTextTokenType.InstructionToken, e)
tt = lambda e: InstructionTextToken(InstructionTextTokenType.TextToken, e)
tr = lambda e: InstructionTextToken(InstructionTextTokenType.RegisterToken, e)
ti = lambda e: InstructionTextToken(InstructionTextTokenType.IntegerToken, e, int(e, 16))
ta = lambda e: InstructionTextToken(InstructionTextTokenType.PossibleAddressToken, e, int(e, 16))
ts = lambda e: InstructionTextToken(InstructionTextTokenType.OperandSeparatorToken, e)
opcodes = {
0x0: "pushread_i_f",
0x1: "push_m",
0x2: "push32_i_i",
0x3: "popwrite_i_f",
0x4: "pop_m",
0x5: "dup",
0x6: "add",
0x7: "sub",
0x8: "mul",
0x9: "mod",
0xa: "xor",
0xb: "and",
0xc: "or",
0xd: "shr",
0xe: "shl",
0xf: "not",
0x10: "neg",
0x11: "nop",
0x12: "exit",
}
registers = [
"ip",
"sp"
]
class Stream:
i: int
buf: bytes
def __init__(self, buf) -> None:
self.pos = 0
self.buf = buf
def read_u16(self) -> Optional[int]:
try:
val = struct.unpack("<H", self.buf[self.pos:self.pos + 2])
self.pos += 2
return val[0]
except:
return None
def read_i16(self) -> Optional[int]:
try:
val = struct.unpack("<h", self.buf[self.pos:self.pos + 2])
self.pos += 2
return val[0]
except:
return None
def read_u32(self) -> Optional[int]:
try:
val = struct.unpack("<I", self.buf[self.pos:self.pos + 4])
self.pos += 4
return val[0]
except:
return None
def read_i32(self) -> Optional[int]:
try:
val = struct.unpack("<i", self.buf[self.pos:self.pos + 4])
self.pos += 4
return val[0]
except:
return None
class Operand:
pass
class Register(Operand):
index: int
name: str
def __init__(self, index: int) -> None:
self.index = index
self.name = f"r{hex(index)}"
class Mem(Operand):
index: int
name: str
def __init__(self, index: int) -> None:
self.index = index
self.name = f"m[{hex(index)}]"
class Imm(Operand):
value: int
unsigned: int
def __init__(self, value: int) -> None:
self.value = value
self.raw = struct.unpack("<I", struct.pack("<i", self.value))[0]
class Instruction:
opcode: int
operands: List[Operand]
addr: int
name: str
size: int
def __init__(self, opcode, operands, addr, opcodes) -> None:
self.opcode = opcode
self.operands = operands
self.addr = addr
self.name = opcodes[self.opcode] if self.opcode in opcodes else "invalid"
self.size = 2 * (len(operands) + 1)
@staticmethod
def disassemble(data: bytes, addr: int, opcodes = opcodes, registers = registers) -> 'Instruction':
stream = Stream(data)
opcode = stream.read_u16()
operands = []
if opcode not in opcodes:
return Instruction(opcode, [], addr, opcodes)
mnemonic = opcodes[opcode]
mnemonic_decomp = mnemonic.split('_')
mnemonic_decomp.pop(0)
for element in mnemonic_decomp:
if element == 'i':
value = stream.read_i16()
operand = Imm(value)
operands.append(operand)
elif element == 'm':
value = stream.read_u16()
operand = Mem(value)
operands.append(operand)
elif element == 'f':
n_regs = operands[-1].value
for i in range(n_regs):
index = stream.read_u16()
operand = Register(index)
operands.append(operand)
return Instruction(opcode, operands, addr, opcodes)
def to_tokens(self) -> List[InstructionTextToken]:
tokens = [tI(self.name)]
for op in self.operands:
tokens.append(tt(" "))
if isinstance(op, Register):
tokens.append(tr(op.name))
elif isinstance(op, Mem):
tokens.append(tr(op.name))
elif isinstance(op, Imm):
if "rel" in self.name or self.name == "call_imm":
tokens.append(ta(str(hex(self.jmp_dest()))))
else:
tokens.append(ti(str(op.value)))
tokens.append(tt(" ("))
tokens.append(ti(str(hex(op.raw))))
tokens.append(tt(")"))
return tokens
def info(self) -> InstructionInfo:
info = InstructionInfo()
info.length = self.size
if "exit" in self.name or "stop" in self.name or self.name == "ret":
info.add_branch(BranchType.FunctionReturn)
return info
class Megalosaure(Architecture):
name = "megalosaure"
address_size = 2
default_int_size = 4
instr_aligment = 2
max_instr_length = 12
regs = {reg: RegisterInfo(reg, 4) for reg in registers}
stack_pointer = "sp"
def get_instruction_text(self, data, addr):
instruction = Instruction.disassemble(data, addr)
return instruction.to_tokens(), instruction.size
def get_instruction_info(self, data, addr):
instruction = Instruction.disassemble(data, addr)
return instruction.info()
def get_instruction_low_level_il(self, data, addr, il):
pass
Megalosaure.register()
arch = Architecture["megalosaure"]
Remember the start_pod and check_format functions ?
The check format passed a specific byte code to only 5 children.
This is probably a good first look
Here is how the plugin looked like on the check format bytecode:
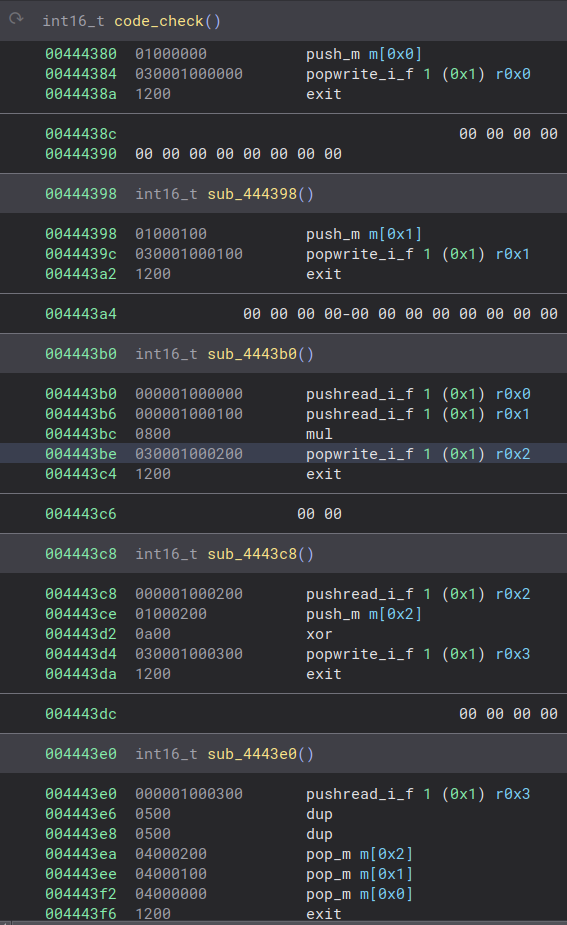
Every function defined here is a specific child.
The first one pushes the first uint32_t of the shared_memory
(I wrote this as m[0x0] in the disassembler)
on the stack, then pops it and writes it on the first pipe (r0x0).
I consider pipes as registers.
The second child does the same but with m[0x1] and r0x1.
Third child reads r0x0, then r0x1, multiplies the two values
and writes the result to r0x2
Fourth child reads r0x2, pushes m[0x2], xor both values,
and writes the result to r0x3.
Finally, the last child reads r0x3, dupplicates the value on the
stack twice and pop them all in m[0x0], m[0x1] and m[0x2]
If we look again at the check_format function:
uint64_t check_format(int32_t* input)
{
shared_mem[0] = input[0];
shared_mem[1] = 0x1337;
shared_mem[2] = 0xa4e1a60a;
start_pod(5, check_bytecode, 0x78 / 10);
return 0 | shared_mem[0] | shared_mem[1] | shared_mem[2];
}
It checks that once the pod has executed, m[0:3] is all 0.
Doing it in the inverse order, it means that the result of the
xor must be 0, thus input[0] * 0x1337 == 0xa4e1a60a
This small script does the modular inverse the retrieve
input[0]:
#!/usr/bin/env python3
from Crypto.Util.number import inverse
import struct
import os
N = 2**32
def reverse(desired_out, mult):
return ((desired_out) * inverse(mult, N)) % N
first = reverse(0xa4e1a60a, 0x1337)
print(struct.pack('<L', first))
With this output:
$ ./invert.py
b'FCSC'
Good, we are definitely on the right track.
Lifting
Great but now if we look at real pods launched for the flag checking,
they contain thousands of children, and have 2 inputs instead of one
(given through m[0x0] and m[0x1])
We need to do something smart.
We noticed in the check_format example that children essentialy
recover one or two inputs (from memory, immediate, or register),
perform a single operation, and output the result to a register
or memory.
Looking back at the code_size given to start_pod in the main function, we can see that there are at most 9 instructions per child.
So it is unlikely that the real check children can do much more than take inputs, compute a single operation and send its outputs.
The binja plugin must be improved, and we will throw away the
binja part actually.
Instead of disassembling independant children, I need to disassemble a whole pod.
Creating an AST
First thing we can build is each child’s register dependencies. I will simply mark which registers the child reads from and which ones he writes to.
Now, knowing by which register a child is “locked” by reading and which one he “unlocks” by writing, I can build the dependency graph of all children.
To do that I implemented a simple algorithm which marks locked and ready registers and by which child a register was unlocked.
Any child wanting to read a register will be able to do so only if it is unlocked, if it is, I will give the current child a reference to the child which originally unlocked the register it is trying to read. The register will thus be consumed by the child and be marked as locked again.
Any child which wants to write to a regiser will simply unlock the register and mark itself as the one which unlocked it. Obviously, this can only be done if all the child’s registers where consumed, otherwise, the child is still waiting for its input and cannot write its output.
We do this in a loop until all children have been scheduled.
Inspecting the built graph, I quickly notice that all children converge to a single output child and that there is no circular dependency. The graph is thus an AST.
Each node of the AST performs and outputs a single operation based on one or two inputs registers.
The leafs of the AST do not have dependencies, they simply take inputs from immediate values or shared memory.
I also notice that the root of the AST has a single input, which is simply outputed in shared memory.
Further analysis will show me that in the AST of every pod, given
pod number n:
- Only the root child outputs to memory, and at index
n+2 - Only the leafs reads from memory, at indexes
nandn+1
Recalling the objective
As a reminder, here is the for loop which computes the result
tested against the ref.
uint32_t (* input_ints)[0x12] = &input;
for (int32_t i = 0; i <= 0x11; i = (i + 2))
{
shared_mem[0] = (shared_mem[0] ^ input_ints[i]);
shared_mem[1] = (shared_mem[1] ^ input_ints[i + 1]);
for (int32_t j = 0; j < 0x2c; j++)
start_pod(pod_infos[j].n_children, code, 9);
*(uint64_t*)(((((i + (i >> 0x1f)) >> 1) + 0x100) << 3) + shared_mem_original)
= *(uint64_t*)(shared_mem + 0xb0);
shared_mem = &shared_mem[0x2c];
}
The output is recovered from shared_memory[0x2c] (0xb0 is 0x2c * 4) on 8 bytes, which are the output of the two last pods
So we have 0x2c pods, each one outputting the inputs for the next
one.
Once all pods have run, notice we shift, the shared_mem by 0x2c
thus right on the last pods output. Which will be used to xor
the next input for the run of 0x2b pods.
This seems like a cbc mode of operation but I did not made any
link to block ciphers at that time.
I will split the problem by solving each block of 8 input bytes independently.
So I have a reference uint64_t, I want to find the two
uint32_t which will give this output after passing in all
of my 0x2c ASTs.
Do the intstructions backward 🤡
I thought about simply taking the desired output and inverting
every operation since I have the complete AST. However I quickly
noticed it was not possible because of operations like shl, shr, or and and.
These operations plus the fact that our inputs are fetched from multiple leafs of the AST make the whole thing close to impossible to invert.
z3 attempt
This is actually not the attempt I made first but I went back and forth on many ideas so I will explain my failed ideas here so it doesn’t cut the flow of the rest of the writeup.
So at some point I tried to build a z3 solver by traversing the AST.
It did not work out in the end because I found a promising solution which was showing results in parallel.
Now I know that it didn’t find anything because I built the
solver by traversing all the 0x2c ASTs, which is too much
obviously.
Basically my mistake was that at the time, I didn’t know that
the VM was a symetric cipher, thus I has no idea of the unicity
of the input. So I thought that I NEEDED, to add a constraint
on the first input uint32_t (which I knew was FCSC) to
find a single solution.
But now I know that the input of every AST is unique so solving ASTs one by one is much easier.
Lifting to C
My actual first idea was that I knew that the flag started with
FCSC{, which only let me 3 unknown bytes in the first block.
This would be fairly trivial to bruteforce if the VM did not need 3 minutes to compute a single block.
I could have implemented an interpreter on top of the AST, but since I decided to go for the bruteforce solution, I went for it all and transpiled it to C.
#!/usr/bin/env python3
import struct
from pwn import *
from typing import Optional, List
from Crypto.Util.number import inverse
#from z3 import *
opcodes = {
0x0: "pushread_i_f",
0x1: "push_m",
0x2: "push32_i_i",
0x3: "popwrite_i_f",
0x4: "pop_m",
0x5: "dup",
0x6: "add",
0x7: "sub",
0x8: "mul",
0x9: "mod",
0xa: "xor",
0xb: "and",
0xc: "or",
0xd: "shr",
0xe: "shl",
0xf: "not",
0x10: "neg",
0x11: "nop",
0x12: "exit",
}
registers = [
"ip",
"sp"
]
N = 2**32
class Stream:
i: int
buf: bytes
def __init__(self, buf) -> None:
self.pos = 0
self.buf = buf
def read_u16(self) -> Optional[int]:
try:
val = struct.unpack("<H", self.buf[self.pos:self.pos + 2])
self.pos += 2
return val[0]
except:
return None
def read_i16(self) -> Optional[int]:
try:
val = struct.unpack("<h", self.buf[self.pos:self.pos + 2])
self.pos += 2
return val[0]
except:
return None
def read_u32(self) -> Optional[int]:
try:
val = struct.unpack("<I", self.buf[self.pos:self.pos + 4])
self.pos += 4
return val[0]
except:
return None
def read_i32(self) -> Optional[int]:
try:
val = struct.unpack("<i", self.buf[self.pos:self.pos + 4])
self.pos += 4
return val[0]
except:
return None
class Operand:
pass
class Register(Operand):
index: int
name: str
def __init__(self, index: int) -> None:
self.index = index
self.name = f"r{hex(index)}"
class Mem(Operand):
index: int
name: str
def __init__(self, index: int) -> None:
self.index = index
self.name = f"m[{hex(index)}]"
class Imm(Operand):
value: int
unsigned: int
def __init__(self, value: int) -> None:
self.value = value
self.raw = struct.unpack("<I", struct.pack("<i", self.value))[0]
class Instruction:
opcode: int
operands: List[Operand]
addr: int
name: str
size: int
def __init__(self, opcode, operands, opcodes) -> None:
self.opcode = opcode
self.operands = operands
self.name = opcodes[self.opcode] if self.opcode in opcodes else "invalid"
self.size = 2 * (len(operands) + 1)
@staticmethod
def disassemble(data: bytes) -> 'Instruction':
stream = Stream(data)
opcode = stream.read_u16()
operands = []
if opcode not in opcodes:
return Instruction(opcode, [], addr, opcodes)
mnemonic = opcodes[opcode]
mnemonic_decomp = mnemonic.split('_')
mnemonic_decomp.pop(0)
for element in mnemonic_decomp:
if element == 'i':
value = stream.read_u16()
operand = Imm(value)
operands.append(operand)
elif element == 'm':
value = stream.read_u16()
operand = Mem(value)
operands.append(operand)
elif element == 'f':
n_regs = operands[-1].value
for i in range(n_regs):
index = stream.read_u16()
operand = Register(index)
operands.append(operand)
return Instruction(opcode, operands, opcodes)
def to_string(self):
asm = self.name
for op in self.operands:
asm += ' '
if isinstance(op, Register):
asm += op.name
elif isinstance(op, Mem):
asm += op.name
elif isinstance(op, Imm):
asm += f"{hex(op.value)}"
return asm
def transpile(self):
if self.name == "pop_m":
return ''
elif self.name == "push32_i_i":
val = (self.operands[1].value << 0x10) | self.operands[0].value
return f'{val}'
elif self.name == "push_m":
return f'm{self.operands[0].index}'
elif self.name == "add":
return '+'
elif self.name == "sub":
return '-'
elif self.name == "mul":
return '*'
elif self.name == "mod":
return '%'
elif self.name == "xor":
return '^'
elif self.name == "and":
return '&'
elif self.name == "or":
return '|'
elif self.name == "not":
return '~'
elif self.name == "neg":
return '-'
elif self.name == "shr":
return '>>'
elif self.name == "shl":
return '<<'
else:
raise
class Child:
def __init__(self, pod, index):
self.pod = pod
self.index = index
self.offset = (pod.offset + index) * self.pod.code_size
self.code = self.pod.megalosaure.elf.read(self.pod.code_base + self.offset * 2, self.pod.code_size * 2)
self.instructions = []
self.depends = []
self.unlocks = []
self.inputs = []
self.main_instr = None
while True:
instr = Instruction.disassemble(self.code)
self.code = self.code[instr.size:]
self.instructions.append(instr)
if instr.name == 'exit':
break
elif instr.name == 'pushread_i_f':
for reg in instr.operands[1:]:
self.depends.append(reg.index)
elif instr.name == 'popwrite_i_f':
for reg in instr.operands[1:]:
self.unlocks.append(reg.index)
else:
if self.main_instr != None:
raise
self.main_instr = instr
def to_string(self):
asm = ""
for instr in self.instructions:
asm += instr.to_string() + '\n'
return asm
def consume_locks(self, locks):
while self.depends != []:
dependency = self.depends[0]
if locks[dependency][0]:
return
self.inputs.append(locks[dependency][1])
locks[dependency] = (True, None)
self.depends.pop(0)
def is_schedulable(self, locks):
return len(self.depends) == 0
def mark_unlocks(self, locks):
for unlock in self.unlocks:
locks[unlock] = (False, self)
def transpile(self, indent=0):
code = "(\n"
indent += 4
code += ' ' * indent
instr = self.main_instr
op = instr.name
inputs = self.inputs
if len(inputs) == 0:
code += instr.transpile()
elif len(inputs) == 1:
inp = inputs[0]
code += instr.transpile() + inp.transpile(indent)
else:
code += inputs[1].transpile(indent)
code += instr.transpile()
code += inputs[0].transpile(indent)
code += '\n'
indent -= 4
code += ' ' * indent
code += ")"
return code
def z3(self, solver, memory):
instr = self.main_instr
op = instr.name
inputs = self.inputs
output = BitVec(f'{self.pod.index}_{self.index}', 32)
if len(inputs) == 0:
if op == 'push_m':
addr = instr.operands[0].index
mem = memory[addr]
solver.add(mem == output)
elif op == 'push32_i_i':
val = (instr.operands[1].value << 0x10) | instr.operands[0].value
output = BitVecVal(val, 32)
else:
print(op)
elif len(inputs) == 1:
inp = inputs[0]
value = inp.z3(solver, memory)
if op == "pop_m":
addr = instr.operands[0].index
mem = memory[addr]
solver.add(mem == value)
solver.add(mem == output)
elif op == "not":
solver.add(output == ~value)
else:
print(op)
else:
value0 = inputs[0].z3(solver, memory)
value1 = inputs[1].z3(solver, memory)
if op == "xor":
solver.add(output == (value0 ^ value1))
elif op == "or":
solver.add(output == (value0 | value1))
elif op == "and":
solver.add(output == (value0 & value1))
elif op == "add":
solver.add(output == (value0 + value1))
elif op == "sub":
solver.add(output == (value1 - value0))
elif op == "mul":
solver.add(output == (value1 * value0))
elif op == "shl":
solver.add(output == (value1 << value0))
elif op == "shr":
solver.add(output == (value1 >> value0))
else:
print(op)
return output
class Pod:
def __init__(self, n_childs, offset, megalosaure, i):
self.megalosaure = megalosaure
self.n_childs = n_childs
self.offset = offset
self.childs = []
self.code_size = 9
self.code_base = 0x50c0
self.stages = []
self.index = i
for i in range(n_childs):
self.childs.append(Child(self, i))
def build_ast(self):
locks = [(True, None) for _ in range(0x26c9)]
to_schedule = [child for child in self.childs]
next_stage_schedule = [1]
while next_stage_schedule != []:
current_stage = []
next_stage_schedule = []
while to_schedule != []:
child = to_schedule.pop(0)
child.consume_locks(locks)
if child.is_schedulable(locks):
current_stage.append(child)
child.mark_unlocks(locks)
else:
next_stage_schedule.append(child)
to_schedule = next_stage_schedule
self.stages.append(current_stage)
return self.stages
def transpile(self):
code = f"uint32_t m{self.index + 2} = {self.stages[-1][0].transpile()};\n"
return code
def z3(self, solver, memory):
self.stages[-1][0].z3(solver, memory)
class Megalosaure:
name = "megalosaure"
address_size = 2
default_int_size = 4
instr_aligment = 2
max_instr_length = 12
def __init__(self, path):
self.elf = ELF(path)
print('[+] Loading virtual machines')
self.podinfo_addresses = 0x444220
self.pods = []
for i in range(0x2c):
podinfo_b = self.elf.read(self.podinfo_addresses + i * 8, 8)
n_childs = struct.unpack('<L', podinfo_b[:4])[0]
offset = struct.unpack('<L', podinfo_b[4:])[0]
pod = Pod(n_childs, offset, self, i)
self.pods.append(pod)
def build_ast(self):
print('[+] Lifting AST')
for pod in self.pods:
pod.build_ast()
def transpile(self, path, depth):
print('[+] Transpiling to C')
code = "#include <stdint.h>\nuint64_t megalosaure(uint32_t m0, uint32_t m1) {\n"
for i in range(depth):
code += self.pods[i].transpile()
code += f"return (((uint64_t)m{depth + 1}) << 32) | m{depth};\n"
code += "}\n"
print(f'[+] Transpiled to {path}')
with open(path, 'w') as f:
f.write(code)
return code
def z3(self, depth, desired):
print('[+] Building z3 solver')
memory = [BitVec(f'm{i}', 32) for i in range(0x2e)]
memory[0] = BitVecVal(0x43534346, 32)
solver = Solver()
for i in range(depth):
self.pods[i].z3(solver, memory)
m44 = desired % (2**32)
m45 = desired >> 32
solver.add(memory[44] == m44)
solver.add(memory[45] == m45)
print('[+] Running solver')
print(solver.check())
m = solver.model()
print(m)
return code
meg = Megalosaure('./megalosaure')
meg.build_ast()
#meg.z3(0x2c, 0x9b07e7ce91a8a7b5)
meg.transpile('./megalosaure.c', 0x2c)
Running it will give this output, and a file megalosaure.c
$ ./disasm.py
[*] '/home/juju/ctf/fcsc_2024/reverse/megalosaure/megalosaure'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: PIE enabled
[+] Loading virtual machines
[+] Lifting AST
[+] Transpiling to C
[+] Transpiled to ./megalosaure.c
The megalosaure.c file is an implementation of a single run of
all the 0x2c pods.
If you are interesed the disasm.py script also contains the code of my z3 attempt.
Bruteforcing until we win
First block
The first block is trivial to bruteforce so I implemented a
simple bruteforce c program which links against a heavily optimised megalosaure.c.
#include <stdint.h>
#include <stdio.h>
uint64_t megalosaure(uint32_t m0, uint32_t m1);
int main(int argc, char **argv)
{
char m0_c[8] = {'F', 'C', 'S', 'C', '{', '0', '0', '0'};
uint32_t *m0 = (uint32_t *)(m0_c);
uint32_t *m1 = (uint32_t *)(&m0_c[4]);
for (int i = 30; i < 127; ++i)
{
m0_c[5] = i;
for (int j = 30; j < 127; ++j)
{
m0_c[6] = j;
for (int k = 30; k < 127; ++k)
{
m0_c[7] = k;
uint64_t res = megalosaure(*m0, *m1);
if (res == 0x9b07e7ce91a8a7b5)
{
printf("%s\n", m0_c);
return 0;
}
}
}
}
}
With the following Makefile (which also has the final targets for the final
solver)
.PHONY: all run
all: ./solver
./simple: ./megalosaure.c simple.c
gcc -Wno-overflow simple.c megalosaure.c -o simple -O3 -march=native -fno-pie -no-pie
./megalosaure.c: ./disasm.py
./disasm.py
./solver: ./megalosaure.c main.c
gcc -Wno-overflow main.c megalosaure.c -o solver -O3 -march=native -fno-pie -no-pie
run: all
./solver
You can run make simple to build this simple bruteforcer for the first block.
$ ./simple
FCSC{454
Great I have the first 8 bytes of the flag. Now what ?
This strategy will not work on other blocks, where all of the 8 bytes are unknown.
Angr attempt
So since I had the source code, I thought that I could try angr on this one, surprisingly enough, this did not give anything.
For the same reason as z3, doing all the pods at once is just too much.
Reducing the character set
Now things are becoming really nasty for my solver, I was working in parallel on the z3 solver and as I ran it on my first try, I thought
Hey “FCSC{454” does not look like a funny string, maybe this flag is only a hexstring
So I started bruteforcing all the blocks but only on hex digits, which comes back to 2^32 iterations per block, completly doable.
However just remember that before being inputted in the first pod, the input is xored with the output of the previous block.
Since I have the reference array, I know the desired output of all the blocks and can bruteforce them in parralel.
Watch out, the code is dirty.
#include <stdint.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
uint64_t megalosaure(uint32_t m0, uint32_t m1);
int block = 1;
int main(int argc, char **argv)
{
char charset[18] = "0123456789abcdef}";
const uint64_t ref[9] = { 0x9b07e7ce91a8a7b5, 0x9e819eac35e7e97c, 0xfd401d3317aa6b5f, 0xdf16a32fbd9d5587, 0x80c561ac0dab4fae, 0x9237d1ddd368e209, 0x07ebe4f6ee26882c, 0xb72ffd11e878303b, 0x99d2a7dc8267bf3f };
int charset_len = 16;
int pid = 0;
for (int i = 0; i < 7; ++i)
{
if (pid == 0)
{
pid = fork();
if (pid == 0)
{
block++;
}
}
}
char m0_c[8] = {'0', '0', '0', '0', '0', '0', '0', '0'};
uint32_t *m0 = (uint32_t *)(&m0_c);
uint32_t *m1 = (uint32_t *)(&m0_c[4]);
uint64_t res;
uint64_t x_int = ref[block - 1];
char *x = (char*)&x_int;
if (block == 8)
{
charset_len += 2;
}
for (int i0 = 0; i0 < 18; ++i0)
{
m0_c[0] = charset[i0] ^ x[0];
for (int i1 = 0; i1 < charset_len; ++i1)
{
m0_c[1] = charset[i1] ^ x[1];
for (int i2 = 0; i2 < charset_len; ++i2)
{
m0_c[2] = charset[i2] ^ x[2];
for (int i3 = 0; i3 < charset_len; ++i3)
{
m0_c[3] = charset[i3] ^ x[3];
for (int i4 = 0; i4 < charset_len; ++i4)
{
m0_c[4] = charset[i4] ^ x[4];
for (int i5 = 0; i5 < charset_len; ++i5)
{
m0_c[5] = charset[i5] ^ x[5];
for (int i6 = 0; i6 < charset_len; ++i6)
{
m0_c[6] = charset[i6] ^ x[6];
for (int i7 = 0; i7 < charset_len; ++i7)
{
m0_c[7] = charset[i7] ^ x[7];
res = megalosaure(*m0, *m1);
if (res == ref[block])
{
char flag[9];
flag[8] = 0;
uint64_t *flag_ptr = (uint64_t*)flag;
*flag_ptr = *m0 + (((uint64_t)*m1) << 32);
*flag_ptr ^= x_int;
printf("Block %d: %s\n", block, flag);
if (pid != 0)
waitpid(pid, NULL, 0);
return 0;
}
}
}
}
}
}
}
}
}
}
You can run make to compile the solver.
It takes about 20 minutes to run, and prints each block when it finds one.
$ time ./solver
Block 6: 06a5611b
Block 1: 2d32e27c
Block 4: 4016b156
Block 8: 420ac}
Block 7: c18edd32
Block 3: d3418e7a
Block 2: de2d7cf7
Block 5: e4df7f0c
real 21m18,662s
user 107m44,082s
sys 0m0,936s
I then reconstituted the flag manually by pasting each block
FCSC{4542d32e27cde2d7cf7d3418e7a4016b156e4df7f0c06a5611bc18edd32420ac}
After solving the challenge and discussing with its author, I learned that the VM actually implemented a symetric block cipher (SIMON-64-128), with a null IV, and CBC mode of operation.
The key was embeded in the code, so it was actually a whitebox.
Looking back at everything, we can clearly see that one pod is
actually a round of encryption, a block is encrypted through
0x2c rounds, with each block input being xored with the output
of the previous block (0 for the first block), thus the CBC and
null IV.